


Book review: Data Management at Scale
Un trajín...

La no literatura en Data Engineering
Data Management at Scale: pues DDD y self-service con mucho metadata
Tu cara me suena: Data Mesh
Read-only Data Stores y una “Data access layer”
Los datos de las RDS
DDS
¿¿¿Es que nadie piensa en el modelado???
Venirse arriba compartiendo entre dominios
Self-service, sin que se nos vaya de las manos
Leading by example
Metadata
Estado civil: es complicado
Impresiones
Notas y referencias
La no literatura en Data Engineering
La cosa se está poniendo seria en cuanto a Data Management en Mercadona Tech, en el mejor de los sentidos: porque las necesidades lo están pidiendo a gritos y porque es un pollo bastante interesante en el que meterse. Cada vez que me veo en un fregado de éstos, me voy a ver lo que ha hecho gente más lista.

Lo que pasa es que la literatura en Data Engineering está regunlinchi. Hay poca sobre "Lo que inTeresa". La gente referencia el ya sempiterno "Designing Data Intensive Applications", pero no es lo que necesito ahora mismo. Como dice Vicky Boykis [1]:
Kleppmann very clearly knows absolutely everything there is to know about distributed systems, from soup to nuts. (...) But I came away disappointed, because what I was really looking for from the book was a set of heuristics that would tell me how to start at the basement of a distributed system and work my way up to understanding how the various components fit and work together. What I wanted was a blueprint for how to build a house, and what I got instead were comprehensive chapters on different power tools. The author knows everything about distributed systems, but the book doesn’t give a good base for how to think about all of the various parts holistically.
Hay bastantes libros enfocados en tecnologías concretas... y aún así, poco de eso se tiene en pie con el Modern Data Stack [2]. Algún paper majo de infra puedes racanear por ahí [3], o la fantasía de los docs de Gitlab [4]. Pero si no, ya te metes en el maravilloso (sic) mundo desestructurado de los artículos y los podcasts: que están rotos [5] o vacíos [6].
Sin ser espectacular, este "Data Management at Scale" es el que más se acercaría a lo que iba buscando [7]. Está escrito por Piethein Strengholt [8], que un señoro que no parece muy farandulero (lo conocen en su casa a la hora de comer) pero que ha estado unos añitos trabajando en un banco alemán (ABN AMRO) de principal architect, o sea que algo sabrá del tema.
Data Management at Scale: pues DDD y self-service con mucho metadata
Piethein lo ve claro, chutarlo todo a un Data Warehouse o a un Data Lake es montar un gran monolito, igualito que en software: a big ball of mud. Además te trae los problemas inherentes a una "mentalidad de centralización": falta de agilidad, alejamiento del dominio del problema, problemas de ownership…

Por otro lado:
Before we continue, I would like to ask you to take a deep breath and put your biases aside. The need for data harmonization, bringing amounts of data into a particular context, always remains, but something we have to consider is the scale in which we want to apply this discipline. In a highly distributed ecosystem, is it really the best way to bring all data centrally before it can be consumed...?

Y propone su alternativa, la Scaled Architecture. Su idea principal es que no haya integración de todos los datos en un único modelo en un punto central, pero sí una plataforma/catálogo/servicios self-service para facilitar que distintos equipos de distintos dominios puedan distribuir y consumir datos ellos mismos con cierto orden y concierto, y sin estar reinventando la rueda 20 veces.

Tu cara me suena: Data Mesh
Si los principios del Data Mesh [9] son:
Aplicar Domain Driven Design también a los datos. Ya que tenemos bounded contexts para los sistemas operacionales, que definen barreras lógicas de ownership para un equipo y su ubiquitous language dentro del mismo, sometamos a los datos a ese mismo marco.
Mentalidad de producto con respecto a los datos: los datos que generan los equipos también son su producto (que consume el resto de la organización) y deberían ser tratados con el mismo rigor.
Self-service: montemos una plataforma para evitar esfuerzo duplicado a los equipos pero que puedan operar estos mismos equipos.
...pues, sí, efectivamente, son los mismos principios. El autor no lo esconde: lo que hace es expandir la idea de la autora original, Zhamak Dehghani (que ojo, porque ella está preparando su propio libro [10]).
Read-only Data Stores y una "Data access layer".
En el diagrama anterior, vemos tres formas de distribución de los datos: vía API, via streaming de eventos y vía las read-only data stores (RDS). Y efectivamente, el libro también le dedica un capítulo a buenas prácticas de APIs y otro a eventos, pero sobre ellos hay mucha más literatura, así que me centraré en las RDS, que son la madre del cordero junto con el data layer.
Haciendo un poco de zoom, tienen esta pinta:
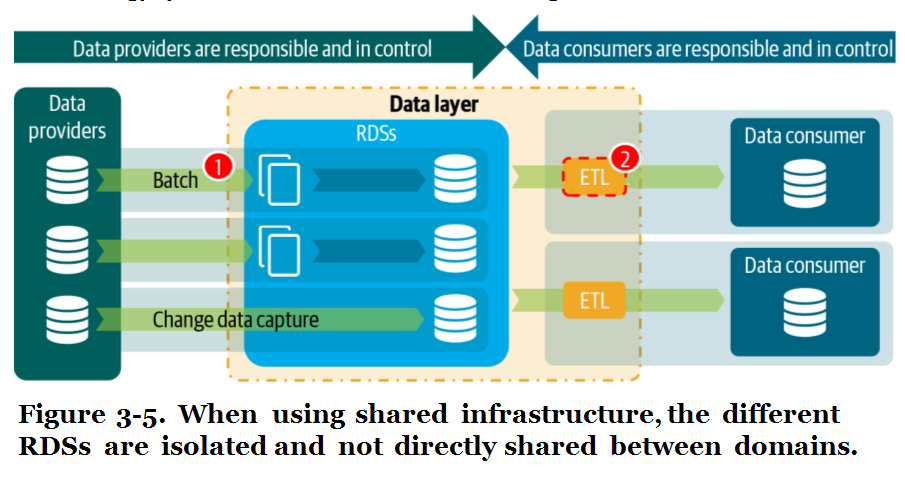
Y aquí es donde se resuelve el misterio de qué quería decir él con un "Data layer" centralizado pero sin centralización de datos: que no tengas un modelo común al que amoldarse (ni un único tipo de storage), sino distintos almacenes de los que se hace cargo cada dominio:
Ideally, multiple RDSs would be hosted on the same physical platform, but they are isolated (...). The key to engineering shared platforms and RDSs is to provide a set of central foundational and domain-agnostic components and make various design considerations in order to abstract repetitive problems from the domains. (p. 59)
Sobre los que, yendo más lejos, puedes ofrecer una capa de virtualización sobre las distintas RDS a lo Presto [11].

Los datos de las RDS
Lo primero de todo es que los golden datasets [12] solo deberían distribuirse desde los sistemas originales. Solo se copian datos a otro dominio si se va a generar nuevo dato a partir de él.

Los datos que exponen los dominios, igual que hacemos con las APIs, no deberían exponerse tal cual se usan internamente en el dominio:
In the data lake, the data is typically pulled straight in as a one-to-one copy from the source. The data and interfaces are tightly coupled with the underlying source systems, so any source system change will immediately break the production pipeline (p. 44)
Dumping in the data raw (one-to-one) with all its complexity might deliver short-term benefits but isn't viable in the longer term (p. 170).
Es decir, debería esconder detalles técnicos, estar orientada a consumo (denormalizada, con nombres friendly...). Eso sí, con el ubiquitous language del dominio que expone.

Esto no quita para no tener una zona en la(s) plataforma(s) que usemos, con otros datasets menos cuidados, más crudos para exploración rápida.

DDS
Esa DDS "misteriosa" que aparece en la imagen anterior es una "Domain Data Store": un sitio en el que guardar los datos de la RDS de otro dominio en caso de que no puedas usarla directamente (por ejemplo porque tengas que hacer determinadas transformaciones). Y esta DDS pues puede ser, ni más ni menos, que una BBDD operacional en el dominio de destino (o el tipo de BBDD que haga falta).
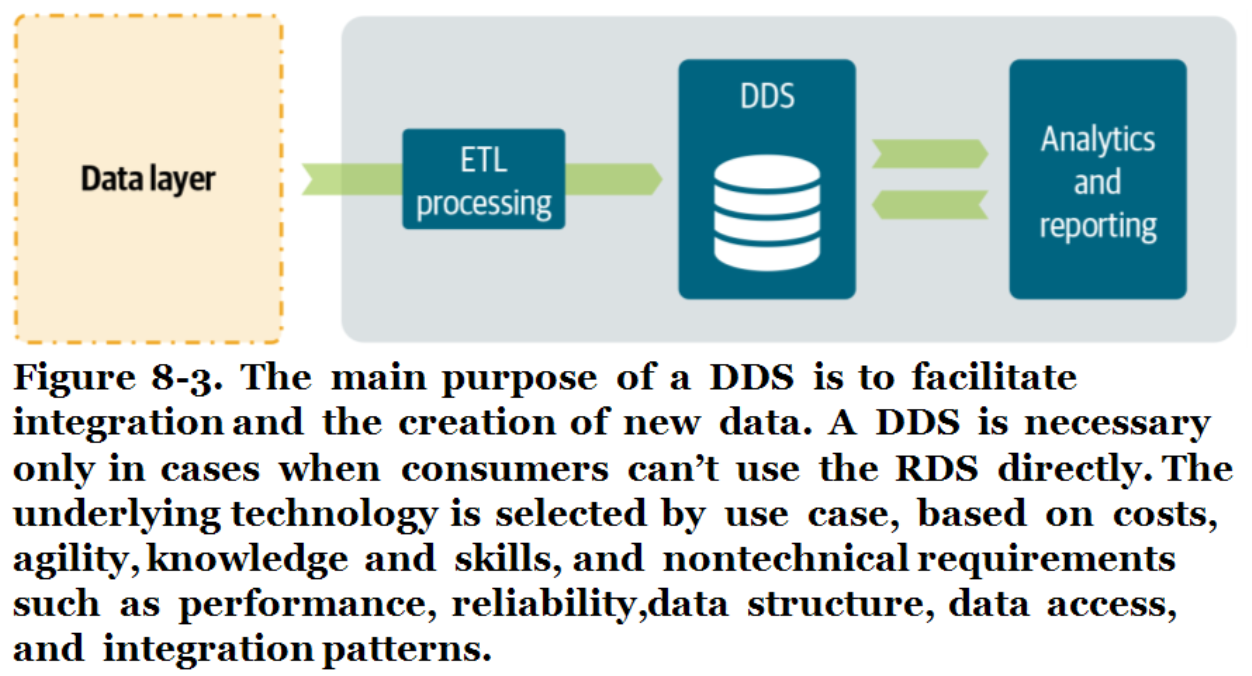
¿¿¿Es que nadie piensa en el modelado???
Pues esa es la historia, que en las RDS y DDS, cada dominio hace un poco lo que vea conveniente. En una breve discusión sobre tipos de stores a usar, sí que recomienda los viejos conocidos del lugar, i.e., Data Vaults alimentando data marts de Kimball. Este articulazo [13] de nuestros compis de Picnic explican ambas y su composición delux.
Venirse arriba compartiendo entre dominios
Hasta aquí, la cosa es muy sencilla porque hablamos de producción de datos de un equipo A (que usa lo que le venga en gana como RDS) y consumo por otro equipo B, que lee de la RDS del equipo A directamente o transforma esos datos y los guarda en una DDS en el dominio del equipo B. Pero por muy bien que hayamos separado dominios en una compañía, surgirán necesidades comunes entre equipos y la necesidad de combinar datos de distintos equipos.
¿Que resulta que las transformaciones que acaban en una DDS le interesan a más de un domino? Pues como en DDD, a compartir en formato shared kernel las transformaciones y DDSs que toquen. Del Domain Driven Design de Eric Evans [13]:
Designate some subset of the domain model that the two teams agree to share. Of course this includes, along with this subset of the model, the subset of code or of the database design associated with that part of the model. This explicitly shared stuff has special status, and shouldn't be changed without consultation with the other team. Integrate a functional system frequently, but somewhat less often than the pace of continuous integration **within the teams. At these integrations, run the tests of both teams (p. 355)
Eso sí, Paco, cuidao, si quisiéramos redistribuir ese dato derivado, ha de hacerse a través del data layer (con su metadata, su discoverability):

Distributing integrated data creates new dependencies, so consider breaking the data down into small, highly focused pieces that solve only one specific problem. Limit the shared domain model to a bare minimum. Don't create a distributed monolith that all teams rely on (p. 234).
Pero ay amiga, date cuenta, que como el mismo autor dice desde el inicio, las necesidades de integración siempre van a estar ahí. ¿Qué ocurre con los datos que son importantes para múltiples dominios? ¿Aquellos que nos va el negocio en ello en que sean consistentes company-wide (e.g., datos de nuestros clientes). Pues no nos escapamos del monstruo del acoplamiento masivo: la disciplina del Master Data Management (MDM). En el capítulo que le dedica a esto, sugiere cuatros estilos distintos de MDM:
Consolidación: que sería el modelado "tradicional" de centralizar datos en un warehouse (o sea que volvemos aquí después de todo, aunque con un subset de los datos).
Coexistencia: que es el más complejo. Igual que el de consolidación, pero en el que los datos maestros, una vez curados, viajan de vuelta a los golden systems:

Y luego dos bastante esotéricos:
Centralizado: donde todos los sistemas han de alimentarse directamente del hub central (WTF).
Registro: solo se almacena de manera centralizada las referencias cruzadas entre los objetos de los distintos dominios que se refieren a la misma entidad. Se les asigna una identificación maestra y punto, a correr.
Eso sí, el autor nos recalca que elijamos muy bien qué datos (y qué atributos de esos datos) realmente necesitamos tener bajo el MDM:
With MDM, it's easy to fall back into the trap of enterprise data unification: widening your scope and mastering too many data results will cause data integration, governance, and coordination to grow dramatically (p. 257).
Y su santo grial para guiar las decisiones, como para casi todo, es el metadata:
The solution lies within metadata. From the lineage, data models, and sharing agreements, you can find overlap and common interest areas between domains and thus determine the scope.
Self-service, sin que se nos vaya de las manos
Leading by example
Al principio todo es self-service by default:
In the absence of specific analytical capabilities and with the need for better speed, business users started to purchase and deploy their own tools themselves (...). The consequence is a diverse collection of tools: the architecture became complex, difficult to manage, and more expensive. (p. 223)
Pero si no vamos poniendo andamios, pues lógicamente vamos cuesta abajo y sin frenos:
Teams that deploy the data services themselves and simply replace data silos with other data services run the risk of "data sprawl". Reusability, consistency, and data quality are important aspects of the new architecture. Consistent communication, commitment, and strong governance are required to scale up. (p. 50)
Para empezar, el equipo de data no debería intentar "to boil the ocean". Ha de empezar a poquitos pero sí que tiene que ir construyendo un catálogo que sirva de ayuda a los equipos:
a common set of reusable database technologies and patterns (...) a catalog to stitch all of the integration architectures together (...) strict principles when teams build data pipelines (...) categorizing all ETL products and frameworks in a unified portfolio (p. 227 a 229).
¡Casi na! Pero vamos, que pongas ejemplos y estandarices, o tienes una zorrera en dos minutos.
Metadata
Aún así, la auténtica clave para un buen data management según el autor es el metadata, hasta el punto de que es lo que le llevó a escribir el libro:
The area of DAMA-DMBOK than needs more work and inspired me to write this book is data integration and interoperability. My observation is that this area hasn't been well enough connected to metadata management. Metadata is scattered (...). The interoperability of metadata — the ability of two or more systems or components to exchange descriptive data about data — is underexposed because building and managing a large-scale architecture is very much about metadata integration. It also isn't well connected to the area of data architecture. If metadata is utilized in the right way, you can see what data passes by, how it can be integrated, distributed, and secured, and how it connects to applications, business capabilities and so on. There is limited documentation about this aspect in the field (p. 4).
Al principio tiras millas con poca cosa, pero...
The troubles, however, arise when companies start to grow. Travel time between departments increases, more people have different focus points, knowledge is scattered, decisions take longer, responsibilities become unclear, and so on. Organization, accountability, and transparency become more urgent as data consumption and usage increase. The need for governance becomes obvious (p. 186)
A lo largo del libro y culminando en un capítulo exclusivo para ello, hace una propuesta "no exhaustiva" de referencia de metadatos:

…sin contar con la parte relacionada con seguridad, que también la trata pero la omito aquí. Toda esta info estaría repartida por distintos repositorios, que se integrarían en una capa fina de orquestación, un data marketplace portal:

Estado civil: es complicado.
Nos pinta un escenario bastante feo con esta movida, a pesar de mostrarnos cómo todos los grandes de turno (Airbnb, Uber, LinkedIn...) lo están haciendo. Lo primero es que, lógicamente, es una tarea ardua.
My experience is that the capabilities offered by the different vendors are mostly area-specific and tightly coupled with other capabilities from the same vendor. This can be contradictory as each organization typically has many domains (...) Building a data catalog yourself (...) is a tremendous task (...). Also vital is that you avoid the pitfall of using these commercial tools as your primary backend system for all metadata. Try to stay as decoupled you can (p. 283).
Aunque sugiere alguna solución open source que tiene pintazo, como CKAN [15]. Sin embargo, no nos abre la puerta a poder tener un self-service flojito mientras vamos levantando este Leviatán:
Metadata management must have a high organizational maturity before a self-service data marketplace architecture can be developed. When the data and metadata are scattered, isolated by tools or teams, and noninteroperable, it will be impossible to provide a unified view of what data is available. If you read articles by the big tech companies, you'll quickly learn that they all either consolidate their metadata or unify all of their APIs through a wapping layer (p. 283).
Por si esto fuera poco, si todo esto del Scaled Architecture (o el Data Mesh) va de empujar el ownership a cada equipo, nos vamos a encontrar bastante resistencia:
The design methodologies discussed in this section require a lot of discipline and attention to quality from the domain teams. They also require ownership to be clearly set (p. 173).
...conceptual data models are often absent is that people question the added value of creating them. Within agile development processes, or under time pressure, I have seen people decide not to capture any implicit thoughts or concepts at all. In such situations, business users, developers, and engineers take shortcuts to deliver the application on time. (p. 269)
Self-service can make or break your new architecture. If users find the architecture difficult to use, it all falls apart (p. 285).
¿Conclusión? El equipo de Data Engineering se tiene que pegar un currazo:
Design it like a series of small, intuitive ecosystems. Each architecture building block must be managed and provided as "reusable services" that work together to provide a full experience. Good API documentation, excellent onboarding, and making the process self-explanatory and easy to use ar the key differentiators for a successful company-wide implementation. Users tend to follow the path of least resistance. If, for example, data lineage is hard but the new architecture fulfills this need in a user-friendly and quicker way, users will be much less likely to fill in the lineage gap themselves. The easier it is to use the new architecture, the more users will adopt it (p. 285).
Impresiones
Se me quedan sensaciones encontradas del libro. Cuando lo leí, la sensación fue de ser farragoso, difícil de asimilar, demasiado genérico en ocasiones, y en otras incluso esotérico. De hecho, creo que es uno de los libros que más me ha costado resumir.
Por otro lado, creo que es algo esperable en este tipo de libros "ontológicos". Intentar hilar un campo extenso, relativamente menos trabajado que otros, con todos sus trade-offs y transmitirlo con buena estructura y sencillez... pues es necesariamente complicado, y complicado también de asimilar por parte del lector. Eso sí, por ejemplo, no recuerdo haber "sufrido" tanto con el "Fundamentals of Software Architecture" [16].
Pero finalmente, la sensación al concluir el resumen es muy buena, creo que es un buen libro y que requería era estas horas de trabajo para sacarle el jugo. Quizá sí que sigo pensando que hay algo de "cruft" (ay, la banca corporate), pero está bastante completo, y es práctico, lo cual es difícil teniendo un scope tan grande y luchando por ser agnóstico en las tecnologías (aunque está plagado de ejemplos de tecnologías que puedes usar para implementar una determinada idea). Y tiene aún más contenido que el que recojo aquí, sobre gobernancia, seguridad, e incluso una discusión (algo esotérica, para que nos vamos a engañar), sobre construirse un Enterprise Knowledge Graph colaborativo sobre los datos de tu empresa, usando los estándares de la semantic web.
Me renta.
Notas y referencias
[1] The attic and the basement of apps · Vicki Boykis
[2] The modern data stack: past, present, and future
[3] [2104.00087] Real-time Data Infrastructure at Uber
[5] Most tech content is bullshit - aleksandra.codes
[6] Mr. Obviedades - by Dr. Mario - Dr. Mario's patchwork
[7] Otro que también está muy bien es el The Self-Service Data Roadmap. Pero hay auténticas castañas por ahí, como el Machine Learning Engineering.
[8] Piethein Strengholt | LinkedIn
[9] How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
[10] Data Mesh [Book]
[11] Presto | Distributed SQL Query Engine for Big Data
[12] Golden datasets son aquellos generados por las golden sources... (lol): es decir, los datos originales generados por las aplicaciones.
[13] Domain-Driven Design: Tackling Complexity in the Heart of Software [Book]